Git - Internal Data Models

When I started my developer career, I was not aware of version control systems. I used to send codes in a
compressed format (with date and some version name as a filename) to other folks who happens to be new
recruits as well (Silly us :P). Then one fine day, one of my senior colleague introduced to me a tool so called “Git”.
Initially I’m not aware of its significances, not completely impressed, but finally managed to learn some common commands for my day-to-day works. The following meme exactly tells my story during those days!

Fast forward to 2020, I’ve broadened my knowledge on git commands and its usage, but still felt I’m missing something.
- How does git manages the history?
- What happens when I make a commit?
- Does git takes a copy of my entire working directory for every commit I make?
- If so, how does memory management works as the time goes?
All these questions arbitrarily pops up in my mind. So I decided to sit down, dig out a bit more about the internals of git and write down a short blog on the things I have learnt on this subject. So here we go!
Git’s Data Model
Git models the history of a collection of files and folders within some top-level directory as a series of snapshots. A snapshot is nothing but a complete capture (state of folder and files) of our working directory at a given time.
In Git terminology,
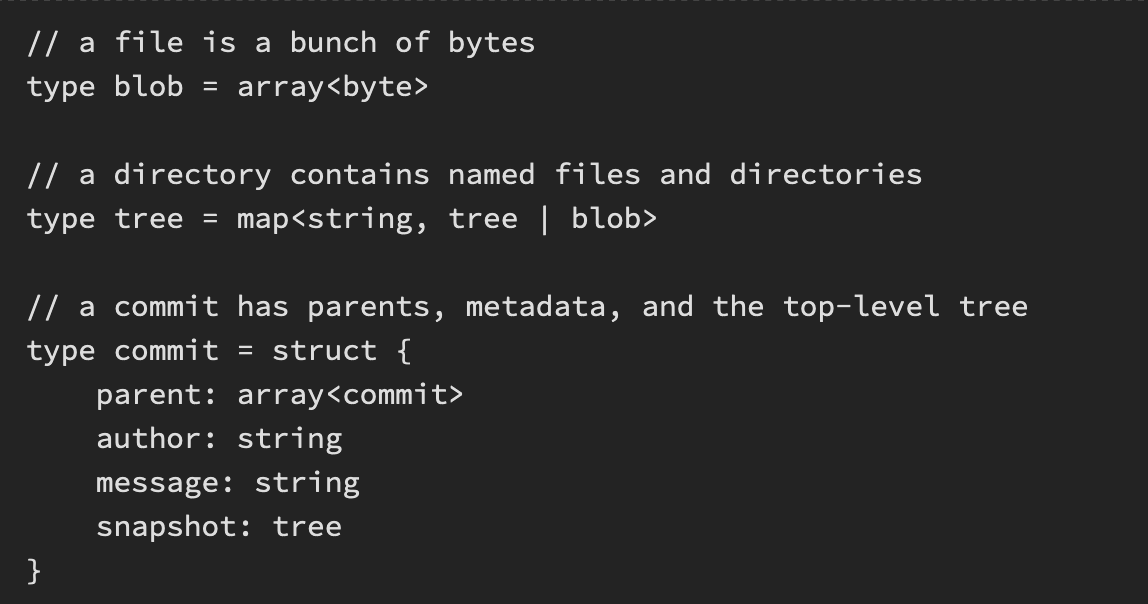
- A file is called a “blob”, and it’s just a bunch of bytes.
- A directory is called a “tree”, and it maps names to blobs or trees (so directories can contain other directories).
- A snapshot is the “top-level tree” (commit) that is being tracked. For example, we might have a tree as follows:
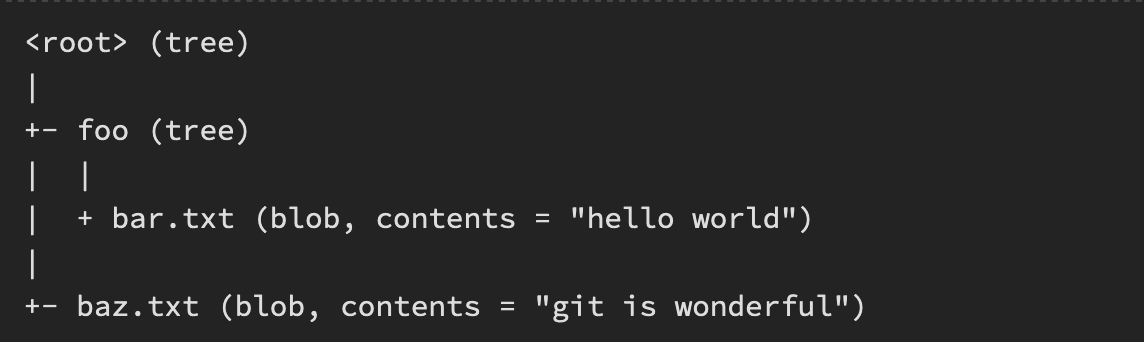
The top-level tree contains two elements, a tree “foo” (that itself contains one element, a blob “bar.txt”), and a blob “baz.txt”. Now let’s dive into three main components (blob, tree and commit) in git for managing data. All other git functionalities are built on top of this.
Blob
Lets start with some hands on. Create a directory and add a file to it
|
|
I haven’t initialised it as a git repo yet. but still i can try some git commands to know what’s going on.
First I want to know what hash_id git is going to store my foo.txt
|
|
If you run this command on your system, you’ll get the same hash_id (as long as content is same). Lets try something more!
|
|
As you can see I created a new file named new_foo.txt but added the same content to this file.
Although the file name was different, the hash_id returned is same. So in git the hash_id is same
for the same content regardless of filename, created_time, author or machines (because no metadata about
the file will be stored in the blob). This type of behaviour is called as pure function,local reasoning or
deterministic algorithm in various programming paradigm.
The next step is to initialize a new repository and commit the file into it.
|
|
At this point our blob should be in the system exactly as we expected, using the hash id determined above. As a convenience, Git requires only as many digits of the hash id as are necessary to uniquely identify it within the repository. Usually just six or seven digits is enough:
|
|
I haven’t even looked at which commit holds this blob, or what tree it’s in, but solely on the hash_id it generated and there it is! In this way, a blob represents the fundamental data unit in Git. Really, the whole system is about blob management.
Trees
Trees in a git are directories which holds another tree or a blob. The tree in git is Map which contains
the name of the tree as a key and its contents in the value.
Blob by itself is featureless, it doesn’t have a name or any structure. In git, to represent the structure, blobs are connected as leaf nodes to the tree. We cannot find the parent tree of the blob from the hash_id of the blob, because there are lot other trees may use the same blob (same content in different file in different directory). But we know it exists in some tree within the previous commit
|
|
Ah! the first commit we made has a tree with a single blob as a leaf node. But still we can’t find the tree hash_id. Okay let’s start from top-down approach staring with commit
|
|
There it is! our blob foo.txt is hanging at tree b520dbc.
Commit
Commit aka “Snapshot” is the one which determines what are the changes happened to our working directory, creates a tree and attaches a blob to it. Every commit has one tree and also contain metadata about that particular commit.
I’m sure all git users will agree that they used git add <file_name> & git push way more than any
other git command. Let understand the workflow behind this by using some low-level git apis.
Let’s start from the scratch again.
|
|
The last command git add <file_name> is the place where we actually tell the git, that something
has changed and we want to capture it by adding it to the index. We still haven’t created the tree or commit
to take a snapshot of this change. But this is the place where the blob are created from the file.
Lets visualize it!
|
|
When we index foo.txt file, it has already created a blob for that. Now we need a tree
to hang hold of this blob.
|
|
The above command will create a tree and attach all the indexed files (in our case foo.txt) to it.
Now we need to create a commit and assign this tree to it.
|
|
The raw commit-tree command will create a commit using the tree provided in args. You can also specify
the parent of this commit by passing the -p option. Still we have few things pending, we have update the
master refs to point this commit and HEAD to point master.
|
|
Finally we made the commit and updated the refs accordingly!
|
|
So we created a blob, tree and a commit in my repository. But how do we verify it? There is a command to do that.
|
|
As expected we have three objects in our repository and their types are mentioned above.
But wait, did I say objects? Have we talked about it before?
Objects and Addressing
In git, Object can be ‘blob, tree or commit’ and all these three are stored as object in an Map<string, string>
Objects are referenced by the SHA-1 hash and the value of that is the corresponding object.
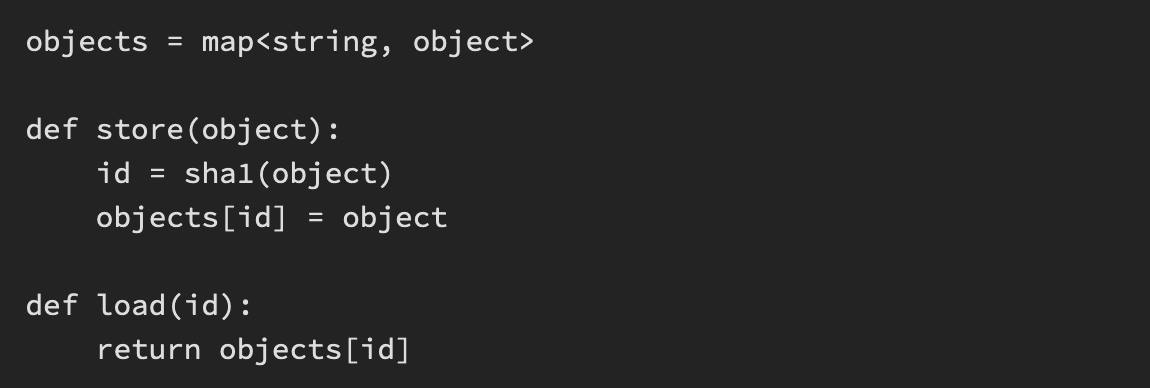
Using this hash_id, one object refers the other. But we have to keep in mind that those
are just pointers to the objects rather than then object itself. For instance in our current working tree
lets cat-file the tree that we have created.
|
|
Here the tree (and commit) doesn’t contain the actual blob but the reference (hash_id) to that particular blob. But we check blob reference we will get the actual content.
References
Now, all snapshots can be identified by their SHA-1 hash. That’s inconvenient, because humans aren’t good at remembering strings of 40 hexadecimal characters (or any long random numbers).
Git’s solution to this problem is human-readable names for SHA-1 hashes, called “references”. References are pointers to commits. Unlike objects, which are immutable, references are mutable (can be updated to point to a new commit).
For example, the master reference usually points to the latest commit in the main branch of development.
Similarly in our order to find out where we currently are git has a special reference called HEAD.
Modelling History
A history would be a list of snapshots in time-order. How should a version control system relate snapshots? We can use simple linear history. But for many reasons, Git doesn’t use this. Instead git history is Directed acyclic graph (DAG) of snapshots.
I know that’s one fancy jargon, but all it means is snapshot can have a set of parents (more than one), because a snapshot can descend from multiple parents (Merging). But in case of linear history it can have at most of one parent (Ex: Google docs)

Summary
To summarize, Git uses objects and references as a data model and all the commands we use are basically creating objects and creating/updating references and maintains the snapshot using the special type of graph data structure.
Next time, when you are typing a git command, try to visualize all the changes that goes under the hood!
Till then, Caio! :)